Chapter 3.
Let's start with the notion of a field. When you row reduce a
matrix, or invert a matrix, or solve a system of linear equations, you
need to perform the following operations: addition, subtraction,
multiplication, and division. A field is defined precisely to make
this possible, so a field is a set F with two operations, addition
and multiplication, satisfying various properties (addition makes Finto an abelian group with identity element 0, multiplication makes
![]() into an abelian group with identity element
1, and addition and multiplication are related to each other by the
distributive law). You know several examples: the real numbers
R,
the complex numbers
C, and the rational numbers
Q. Another
important example is the set of congruence classes of integers modulo
a prime number p, written as
Z/ p Z, or to emphasize that it's
a field, as
Fp.
into an abelian group with identity element
1, and addition and multiplication are related to each other by the
distributive law). You know several examples: the real numbers
R,
the complex numbers
C, and the rational numbers
Q. Another
important example is the set of congruence classes of integers modulo
a prime number p, written as
Z/ p Z, or to emphasize that it's
a field, as
Fp.
Given a field F (and if you want, just take F=R or F=C), a vector space over F is a set V together with two operations: addition (also known as ``vector addition''; this makes V into an abelian group), and scalar multiplication. These have to satisfy the axioms listed in Definition 2.11. (See also Definition 1.6 for the special case when F= R.) Standard example: Rn, the length n column vectors with real entries, is a vector space over R. (More generally, for any field F, Fn is a vector space over F.) Any line through the origin or plane through the origin in R3 is a vector space, and is a subspace of R3. The complex plane C can be viewed as a vector space over C, over R, or over Q, just by restricting which sorts of numbers you allow for scalar multiplication.
Now fix a field F and a vector space V over F. The elements of
V are called vectors, of course, and the elements of F are
called scalars. If v1, ..., vn are vectors in V,
then a linear combination of these vectors is any vector of the
form
A basis for a vector space V is a set of linearly independent
vectors in V which also spans V. For some computations, it is
useful to pay attention to the order of elements in a basis, so a
basis is actually an ordered set of linearly independent
vectors which span the space. For example, the following are
(different) bases for
R3:
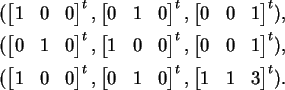
(Standard notation: if you list elements in curly braces - ![]() - that means a set. If you list them in parentheses - (x,y) -
that means an ordered set. So the sets
- that means a set. If you list them in parentheses - (x,y) -
that means an ordered set. So the sets ![]() and
and ![]() are
equal, while the ordered sets (x,y) and (y,x) are different.)
are
equal, while the ordered sets (x,y) and (y,x) are different.)
Proposition 3.8 is important: a set
![]() is a basis if and only if every vector
is a basis if and only if every vector ![]() can be
written as a linear combination of the vi's, in a unique way.
can be
written as a linear combination of the vi's, in a unique way.
On to a discussion of dimension: first, a vector space V is finite-dimensional if there is a finite set of vectors which spans it. (E.g., I gave several different finite sets which span R3.) Assume that V is finite-dimensional; then Proposition 3.17 says that any two bases for V have the same number of elements, so define the dimension of V to be the number of vectors in any basis. (E.g., the dimension of R3 is 3.)
Given a vector space V and a basis
![]() ,
any vector
,
any vector ![]() can be written in exactly one way as a
linear combination
can be written in exactly one way as a
linear combination
Suppose we are working with the vector space
Rn of
n-dimensional column vectors with real entries. The standard
basis for
Rn is
More generally, given two different bases for a vector space V, it is important to be able to convert between one and the other. See pages 97-99 for a discussion of this.
(I'm not going to discuss the material in Sections 3.5 and 3.6 now, but I'll ask you to read them eventually.)
Chapter 4.
Given two vector spaces V and W over a field F, a linear
transformation from V to W is a function
Notice that if we ignore scalar multiplication, then any linear
transformation T is a group homomorphism, so we can define the
kernel and image of T. The kernel is also called the
null space. One important formula is given in Theorem 1.6: for
any linear transformation
![]() ,
,
As it stands, linear transformations are somewhat abstract, while
matrix multiplication is much more concrete. We can remedy this (and
I don't mean by making matrix multiplication more abstract). First we
have to choose a basis
![]() of Vand a basis
of Vand a basis
![]() of W. Then for
each j, T(vj) is in W, so can be written uniquely as a linear
combination of the elements of
C:
of W. Then for
each j, T(vj) is in W, so can be written uniquely as a linear
combination of the elements of
C:
Here's a good example to work out: let Pn be the vector space of
all real polynomials of degree at most n, with basis
![]() .
Then the derivative D is a linear transformation
from Pn to itself. Find the matrix for D with respect to this
basis.
.
Then the derivative D is a linear transformation
from Pn to itself. Find the matrix for D with respect to this
basis.
Another example of a linear transformation: let T be rotation of
R3 by angle ![]() around the line through the origin
determined by the vector
around the line through the origin
determined by the vector
![]() .
I could work out the matrix for this with respect
to the standard basis, but things will be nicer if I use v as, say,
the first element of the basis. Since the linear transformation sends
v to itself, then the matrix will look like
.
I could work out the matrix for this with respect
to the standard basis, but things will be nicer if I use v as, say,
the first element of the basis. Since the linear transformation sends
v to itself, then the matrix will look like
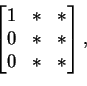
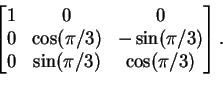
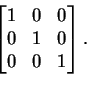
If you change bases in either V or W or both, you get a new matrix for the linear transformation T; how a matrix is transformed when you change bases is discussed on pages 113-115. See Proposition 2.9, in particular.
If V is a vector space, then a linear operator on V is a linear transformation from V to itself. In this case, when computing a matrix for V, you usually pick the same basis for V in its role as domain and in its role as range. Proposition 3.5 says this: if A is the matrix for T with respect to some basis, then when you change bases, you get matrices of this form: PAP-1, where P is in GLn(F). Definition: two matrices A and A'are similar if A' = PAP-1 for some invertible P.
Invariant subspaces, eigenvalues, and eigenvectors are used to study
linear operators on a vector space V. A subspace W of V is
invariant under T if
![]() for all
for all ![]() .
For
example, if
.
For
example, if
![]() is rotation about the
z-axis by angle
is rotation about the
z-axis by angle ![]() ,
then the xy-plane is an invariant
subspace: given any vector v in the xy-plane, then T(v) is also
in the xy-plane. The z-axis is another invariant subspace.
,
then the xy-plane is an invariant
subspace: given any vector v in the xy-plane, then T(v) is also
in the xy-plane. The z-axis is another invariant subspace.
An eigenvector for T is a nonzero vector v so that Tv is
a scalar multiple of v: Tv = cv for some ![]() .
The scalar
c is the eigenvalue associated to the eigenvector v.
Corollaries 3.10, 3.11, and 3.12 are all important.
.
The scalar
c is the eigenvalue associated to the eigenvector v.
Corollaries 3.10, 3.11, and 3.12 are all important.
To find eigenvectors and eigenvalues, rewrite the equation Tv = cvas Tv = cIv, where I is the
![]() identity matrix, and then
rewrite this as
cIv - Tv = 0, or
(cI-T)v = 0. So a nonzero vector
v is an eigenvector of T, with eigenvalue c, if v is in the
kernel of cI-T. A matrix (or linear operator) has nonzero vectors
in its kernel if and only if its determinant is zero, in which case
it's called singular. So c is an eigenvalue for T if and
only if the linear operator cI-T is singular, which is true if and
only if
identity matrix, and then
rewrite this as
cIv - Tv = 0, or
(cI-T)v = 0. So a nonzero vector
v is an eigenvector of T, with eigenvalue c, if v is in the
kernel of cI-T. A matrix (or linear operator) has nonzero vectors
in its kernel if and only if its determinant is zero, in which case
it's called singular. So c is an eigenvalue for T if and
only if the linear operator cI-T is singular, which is true if and
only if
![]() .
.
So, let T be a linear operator with matrix A, let t be a
variable, and define the characteristic polynomial of T to be
![]() .
The eigenvalues of T are the roots of this
degree n polynomial.
.
The eigenvalues of T are the roots of this
degree n polynomial.
(This means that they are the roots of the polynomial that exist in
the field F. So if we decide to work with the field
Q of
rational numbers, then the matrix
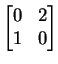 ,
which has characteristic polynomial
p(t) = t2 -
2, has no eigenvalues. It has two eigenvalues,
,
which has characteristic polynomial
p(t) = t2 -
2, has no eigenvalues. It has two eigenvalues, ![]() and
and
![]() ,
if we are working over the field
R.)
,
if we are working over the field
R.)
Corollary 4.14 and Proposition 4.18 are useful.
If T is a linear operator on a vector space V, it is useful to know whether T is similar to an upper triangular matrix or to a diagonal matrix. The characteristic polynomial is important here; see Corollary 6.2 and Theorem 6.4 for the main results.
Go to John Palmieri's home page.